最近把 New API 的监控接入了 Grafana,踩了不少坑。这篇记录完整的搭建过程和踩坑经验。
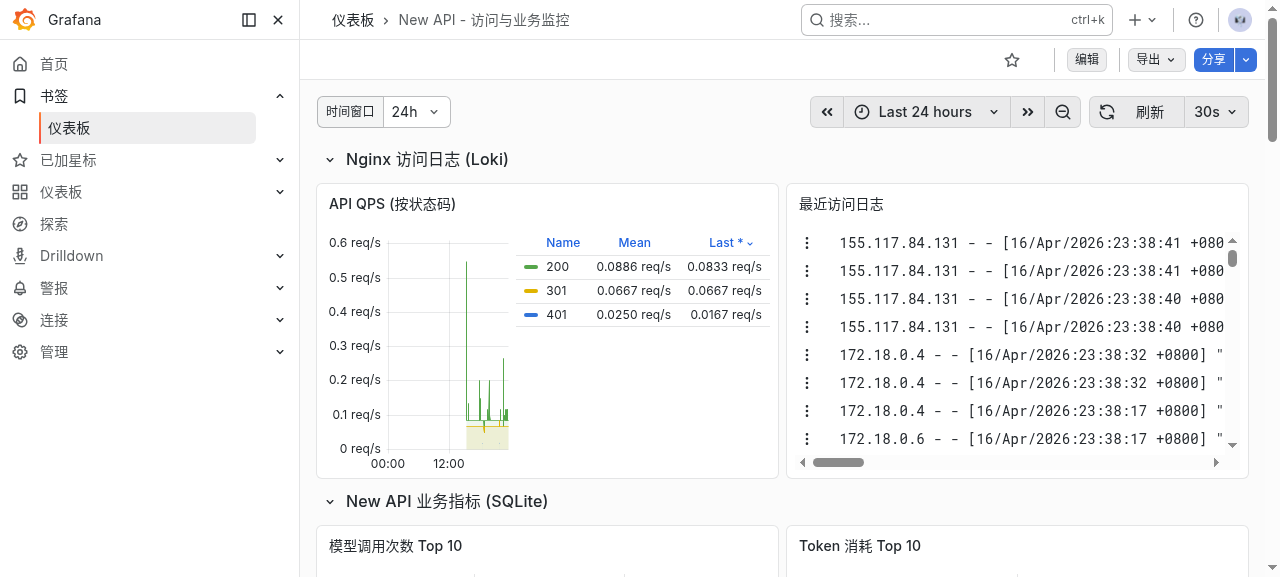
上面这张是当前看板的整体视图,已经能同时看到访问层和业务层两个部分。下面把关键模块拆开讲。
架构概述
我们落地了两套方案:
- 访问层:Nginx access log → Loki + Promtail,看 QPS、状态码、延迟分布
- 业务层:SQLite exporter 读取
one-api.db,暴露模型调用次数、Token 消耗、首字用时(TTFB)、失败率等业务指标
看板地址:https://grafana.codingshen.top/d/newapi-monitoring/140f20c
访问层监控:Loki + Promtail
访问层主要看 Nginx 日志,最直观的是 QPS 和最近访问日志。
从这里能快速看出:
200、301、401的请求趋势- 最近有哪些来源在访问 API
- 是否有异常状态码突然抬头
核心踩坑记录
坑一:SQLite 不是时序数据库
这是最大的约束。New API 的 logs 表记录了每次调用的模型、渠道、Token 数、耗时,但 SQLite 没有 counter/gauge 的时序语义。
问题在于,Grafana 的 $__range 没法直接用,SQLite 不知道“最近 24 小时”是什么意思。
我的解法是:在 exporter 里预计算固定窗口。每次 Prometheus scrape 时,现场跑 SQL 按 1h/3h/12h/24h/7d/30d/all 分桶统计,暴露成不同的 gauge 指标。
# exporter 核心逻辑
"""
SELECT
l.model_name,
COALESCE(c.name, 'unknown') as channel_name,
COUNT(*) as cnt
FROM logs l
LEFT JOIN channels c ON l.channel_id = c.id
WHERE l.created_at >= datetime('now', '-24 hours')
GROUP BY l.model_name, c.name
"""
坑二:62 种历史模型淹没 Top 10
一开始暴露全量历史聚合,看板上蹦出 62 种模型,90% 是几个月前试过就再也没用过的。
解法很直接:给表格加 Top 10 限制,只展示近期活跃的模型。all 窗口作为兜底选项。
坑三:channel_name 全是 NULL
logs.channel_name 字段永远是 NULL。不是 SQL 写错了,而是 New API 写日志时这个字段就是空的,只写了 channel_id。
所以只能 LEFT JOIN channels 去渠道表捞真实名字。
坑四:流式调用被当成全部调用
我一开始硬编码了 type="2"(流式调用),普通调用全被漏了,失败率分母也变小,导致数据失真。
修复方法就是去掉 type 过滤,按全部类型聚合。
坑五:表格展示比图表难做
bargauge单条数据时标签被截断barchart横坐标显示成时间戳(2026)而不是模型名- 数值列的阈值背景色会传染到文本列
最后统一改成 table,再给文本列加 field override 固定颜色。
业务层核心面板
这部分是最有价值的区域,直接回答三个问题:
- 现在谁调用最多
- 谁最烧 token
- 谁最慢、谁最容易失败
这里包含:
- 模型调用次数 Top 10
- Token 消耗 Top 10
- 平均延迟 Top 10
- 配额消耗 Top 10
- 输入缓存命中率 Top 10
从当前截图里已经能很直观看到:
kimi-k2.5调用量和 token 消耗都远高于其他模型gpt-5.4、MiniMax-M2.7是第二梯队- 不同渠道下同一模型的表现并不一样
失败分析与性能分析
看板下半部分是排障最常用的区域。
这里包含:
- 失败次数(按状态码)
- 失败次数 Top 10(按渠道+模型)
- 失败率排行榜(按渠道+模型)
- 失败原因统计
- 性能分析(按渠道+模型,展示首字用时和总用时)
这一块很关键,因为它把“调用多不多”和“到底是不是有问题”分开了。比如:
- 某模型调用量不高,但失败率极高
- 某渠道总体可用,但 TTFB 很差
- 某状态码突然抬头,能立刻从饼图里看出来
关键配置
SQLite Exporter
# docker-compose 片段
newapi-sqlite-exporter:
image: python:3.11-slim
ports:
- "9234:9234"
volumes:
- /root/new-api/one-api.db:/data/one-api.db:ro
environment:
- DB_PATH=file:/data/one-api.db?mode=ro
Prometheus job
- job_name: 'newapi-sqlite-exporter'
static_configs:
- targets: ['newapi-sqlite-exporter:9234']
Loki + Promtail
# promtail-config.yml
scrape_configs:
- job_name: nginx-api
static_configs:
- targets:
- localhost
labels:
job: nginx-api
__path__: /var/log/nginx/api.codingshen.top.access.log
看板面板说明
| 面板 | 说明 |
|---|---|
| 模型调用次数 Top 10 | 按渠道+模型聚合 |
| Token 消耗 Top 10 | prompt + completion 分开统计 |
| 平均延迟 Top 10 | latency_seconds_sum / count |
| 首字用时(TTFB) | 按渠道+模型分组 |
| 失败次数/失败率 | 含状态码饼图和失败原因分类 |
| 缓存命中率 | <30% 红、30-70% 黄、>70% 绿 |
| Nginx QPS & 状态码 | Loki 日志实时计算 |
经验总结
搭建监控看板最大的收获不是 Grafana 玩得有多溜,而是深刻体会了非时序数据硬套时序监控有多别扭。
如果你也在监控类似的业务数据库,建议先想清楚:
- 数据源能不能原生支持时间范围切片?
- 历史垃圾数据会不会淹没当前的 Top N?
- 维度字段(如 channel_name)是不是真的可信?
本文由蛋壳整理,基于实际踩坑经验。
